베하 ~!
문땅훈과 루피입니다.

해가 짧아지는 걸 보면서 겨울이 다가 오고 있다는 것을 체감하고 있는 요즘입니다.
가을 감기 다들 조심하세요!!
오늘은 PaLM에 대해서 알아보고 Vexter AI를 사용해 PaLM을 활용하는 방법을 소개하고자 합니다.
바로 시작하겠습니다.
개요
- PaLM 과 PaML2 소개
- PaLM 활용
1. PaLM과 PaLM 2소개
PaLM을 들어보셨나요? 쉽게 팜 이라고 불리웁니다.
- PaLM(Pathways Language Model)은 구글에서 공개한 5400억개의 파라미터를 사용해 많은 언어 이해 및 생성 테스크에서 좋은 성능을 보인 AI 언어 모델입니다.
- Pathways는 차세대 인공지능(AI) 아키텍처로, 하나의 AI 알고리즘에 영상, 오디오, 텍스트, 이미지 등 다양한 데이터 형식을 포괄하는 다중 학습모드를 지원할 수 있도록 하는 아키텍처이다.
PaLM2는 기존 모델인 PaLM에서 성장한 모델입니다.
- PaLM 2는 3조6천억개의 토큰으로 훈련됐다. 단어 문자열을 의미하는 토큰은 생성하는 문장의 맥락 속에서 다음 단어를 예측하는 트랜스포머 기반 LLM의 주요 구성요소다. 1년전 모델인 PaLM의 경우 7천800억개의 토큰을 학습했다. PaLM 이전의 구글 LLM이었던 LaMDA의 경우 1조 5천억개의 토큰을 학습했다.
- PaLM 2의 매개변수는 3천400억개이며, PaLM의 5천400억개의 63%에 해당
- 최신 모델이 이전 모델보다 더 작은 규모로 만들어진 것이 특이한 점이다.
PaLM 2의 주요 기능을 알아보겠습니다.
1. 사고 사슬
- 사고 사슬(chain-of-thought) 프롬프트를 사용한 PaLM은 다단계의 산술 계산이나 상식 추론 문제에서 획기적인 성능을 보임
- 아래의 이미지는 PaLM이 사고 사슬을 이용해 초등학교 수학 문제를 해결하는 예시이다. 왼쪽은 일반적인 프롬프트이고, 오른쪽은 사고 사슬을 이용한 프롬프트이다. PaLM은 문제를 정확히 맞출 뿐 아니라 정답의 이유까지 명확하게 제시하고 있음

2. 다국어 언어 지원
- PaLM은 29개의 영어 자연어 처리 문제 중 28개의 문제에서 다른 모델(GLaM, GPT-3, Gopher, LaMDA 등)보다 더 높은 성능을 보였음
- 또한, PaLM는 100개 이상의 언어를 학습하였음

3. 코드 생성 및 코드 오류 수정
- 방대한 자연어와 소스 코드에 대한 데이터셋으로 훈련 되었습니다. 파이썬, 자바스크립트 등 다양한 프로그래밍 언어에 뛰어나며 프롤로그, 포트란, 베럴로그와 같은 언어에 특화된 코드를 생성할 수 있습니다.
2. PaLM 활용
- 구글 팜(PaLM) API 이용해 자동으로 블로그 콘텐츠 만들기 예제 입니다. 구글 Vertex AI를 사용하여 팜 API를 사용하는 활용법입니다.
1. Vexter AI에서 Jupyter 노트북으로 google cloud aiplatform을 업그레이드 해줍니다.
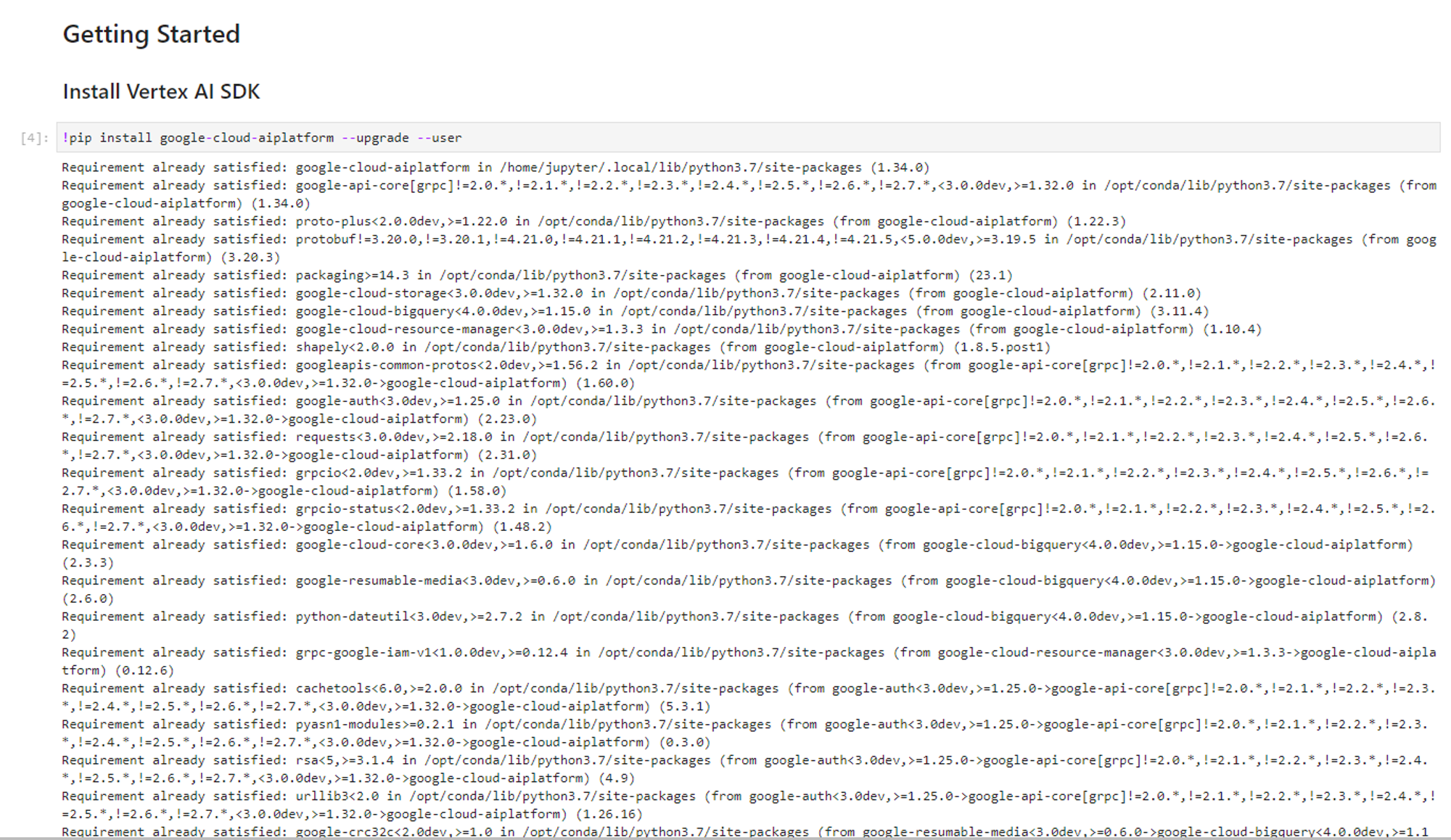
2. 필요한 패키지를 설치해줍니다. 설치 후, 라이브러리를 불러옵니다.
- vertexai.preview.language_models 라이브러리는 ChatModel, TextEmbedding, TextGenerationModel 등 다양한 클래스를 지원합니다.
3. 미리 학습한 text-bison@001 기반 모델 객체를 초기화합니다.
- text-bison@001은 텍스트 생성에 최적화 된 모델입니다.
4. 프롬프트를 입력 받아 글을 생성하고 출력하는 함수 생성
- 프롬프트 매개변수 설명
- max_output_tokens
- 문자열을 의미하며 토큰이라고 나타낸다. 토큰은 보통 4글자 정도이며, 100개 토큰이 60~80단어 정도 된다. 500 단어 이내로 만들고 싶다면 토큰 값을 1000으로 설정하면 된다. PaLM2가 지원하는 최대 값은 1024이다. 매개변수를 지정하지 않는다면 기본값 64로 적용된다.
- temperature
- 모델의 창의성을 규정하는 것으로, 토큰 선택을 어느 정도나 무작위로 할 것 인가를 결정한다. 값이 낮을수록 덜 창의적인 답변을 출력하고 값이 높으면 더 다양하고 독창적인 결과를 반환함.
- top_k
- 확률이 높은 순서대로 k 번째 까지 높은 단어에 대해 필터링 하는 값
- k의 값이 높을수록 모델이 선택할 수 있는 단어는 많아지나. 많아지는 만큼 모델이 불필요 한 단어를 선택할 확률이 높아진다.
- top_p
- 일정 확률값 이상인 단어에 대해 필터링 하는 값
- p의 값이 높을수록 모델이 다양한 단어를 선택할 가능성이 높아지며 다양한 문장을 생성 할 수 있음
- max_output_tokens
5. 프롬프트를 구현합니다.
6. 프롬프트를 전달해 매소드 호출합니다.
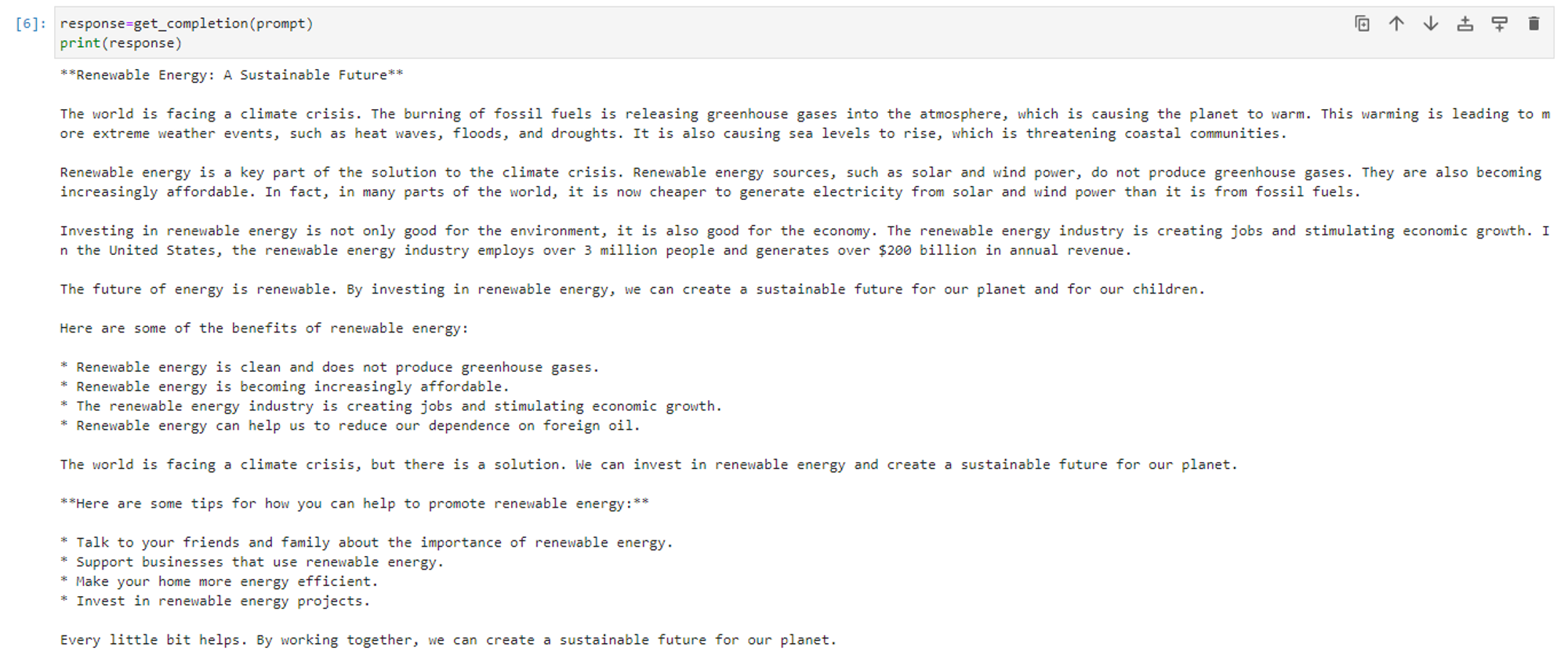
출력값에서 블로그에 대한 글을 확인할 수 있습니다.
PaLM 소개와 활용에 대해서 감이 오시나요!??!
간단한 예제 코드와 함께 알아보아서 재밌고 쉽게 이해할 수 있을 것 같습니다.
다음엔 더 유익한 글로 돌아오겠습니다.
베빠!!

'CSP (Cloud Service Provider) > GCP' 카테고리의 다른 글
| Policy tag를 통한 Bigquery 정보 관리 (1) | 2023.10.13 |
|---|---|
| Cloud DNS Zone의 종류와 생성 (0) | 2023.10.13 |
| [GCP] Cloud Storage와 lifecycle (1) | 2023.10.12 |
| BigQuery - Query의 종류와 결과 쓰기 (0) | 2023.09.30 |
| Vertex AI Workbench란? (0) | 2023.09.27 |

댓글