베하~ 안녕하세요! BTC_현상수배범 입니다.
오늘은 아주아주 간단한 실습을 하나 진행해보려 합니다. 진행 순서는 다음과 같습니다.
1. 문서 로드
2. 로드한 문서를 nodeParser를 통해 노드로 파싱
3. 노드로 인덱스 구성
4. 인덱스 쿼리
5. 응답
위 과정을 통해, 본인이 가지고 있는 데이터(문서 등)를 기반으로 LLM에 질문을 하고, 응답을 받을 수 있습니다.
이번 실습에서는 에세이를 활용하여 저자가 작성한 내용에 대해 QA 태스크를 진행해보도록 하겠습니다.
!! 이 과정을 진행하며 비용이 청구될 수 있으니 주의하시기 바랍니다 !!
1. 문서 로드
링크에 예시 에세이 자료가 있습니다. git clone 명령어를 사용하거나, 링크를 방문하여 txt 파일만 다운로드 하시면 됩니다.
git clone https://github.com/jerryjliu/llama_index.gitgit clone 이후, examples/paul_graham_essay/data 경로에 동일한 에세이 자료가 있으니 확인하시면 되겠습니다.
다음과 같이 문서를 로드할 수 있습니다.
# %pip install -U llama_index
from llama_index import SimpleDirectoryReader
# 에세이 파일이 위치한 디렉터리 명
directory = 'data'
documents = SimpleDirectoryReader(directory, recursive=True, exclude_hidden=False).load_data()
----------------------------------------실행 결과-------------------------------------
DEBUG:llama_index.readers.file.base:> [SimpleDirectoryReader] Total files added: 1
> [SimpleDirectoryReader] Total files added: 1
> [SimpleDirectoryReader] Total files added: 1recursive: [bool] 해당 디렉터리 내부의 모든 파일을 재귀적으로 호출합니다.
exclude_hidden: [bool] 해당 디렉터리 내부에서 숨김 파일도 읽어올지를 설정합니다.
2. 로드한 문서를 nodeParser를 통해 노드로 파싱
노드는 텍스트 청크, 이미지 등 문서의 모든 "chunk"를 의미합니다.
노드에는 다른 노드 및 인덱스 구조와의 메타데이터 및 관계 정보도 포함됩니다.
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser()
nodes = parser.get_nodes_from_documents(documents)
-------------------------------------------실행 결과------------------------------------------
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: What I Worked On
February 2021
Before college...
> Adding chunk: What I Worked On
...
> Adding chunk: 1960 paper.
3. 노드로 인덱스 구성
생성한 노드로부터 인덱스를 구성하도록 합니다.
인덱스는 사용자 쿼리에 대한 관련 컨텍스트를 빠르게 검색할 수 있는 데이터 구조로, <document> 또는 <node>에서 빌드되며, 질문 및 답변과 데이터 채팅을 가능하게 하는 쿼리 및 채팅 엔진을 구축하는 데 사용됩니다. 이번 실습에서는 여러 유형의 인덱스 중, VectorStoreIndex를 사용합니다.
import os
# 자신의 API key로 바꿉니다.
os.environ['OPENAI_API_KEY'] = "YOUR_OPENAI_API_KEY"
# %pip install -U deeplake
from llama_index import VectorStoreIndex, LLMPredictor, ServiceContext, StorageContext, OpenAIEmbedding
from langchain import OpenAI
from llama_index.vector_stores import DeepLakeVectorStore
# define embedding model
embed_model = OpenAIEmbedding(
model="text-embedding-ada-002",
embed_batch_size=10,
)
dataset_path = "deeplake_store"
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI())
vector_store = DeepLakeVectorStore(dataset_path=dataset_path, overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, embed_model=embed_model)
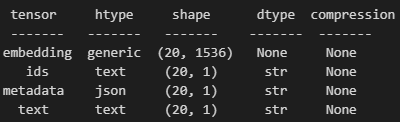
index = VectorStoreIndex(nodes=nodes,
storage_context=storage_context,
service_context=service_context)위 코드를 실행하면 아래와 같이 내용을 확인할 수 있습니다.
4. 인덱스 쿼리
인덱스를 빌드한 후 이제 QueryEngine으로 쿼리할 수 있습니다. "쿼리"는 단순히 LLM에 대한 입력입니다. 즉, 여러분들이 ChatGPT 에게 질문을 하는 것과 동일하다고 보시면 되겠습니다.
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")위 과정을 통해 "What did the author do growing up?"이라는 쿼리를 LLM에 전달했고, LLM이 응답한 내용이 response라는 객체에 저장되었습니다. llama_index.response.schema.Response type으로 저장되었습니다.
이후, LLM이 응답한 결과를 출력해볼 수 있습니다.
print(response)
--------------------------------------------실행 결과----------------------------------------
Growing up, the author wrote short stories, experimented with programming on an IBM 1401, and eventually convinced his father to buy him a TRS-80. He wrote simple games, a program to predict how high his model rockets would fly, and a word processor for his father to write a book. He then switched to studying philosophy in college, before eventually deciding to switch to AI. He also wrote essays, worked on spam filters, did painting, and learned how to cook for groups of friends.
Querry: 저자는 자라면서 무엇을 했습니까?
response: 자라면서 저자는 단편 소설을 쓰고 IBM 1401에서 프로그래밍을 실험했으며 결국 아버지에게 TRS-80을 사달라고 설득했습니다. 그는 간단한 게임, 자신의 모델 로켓이 얼마나 높이 날아갈지 예측하는 프로그램, 아버지가 책을 쓸 수 있도록 워드 프로세서를 만들었습니다. 그런 다음 대학에서 철학 공부로 전환한 후 결국 AI로 전환하기로 결정했습니다. 그는 또한 에세이를 쓰고, 스팸 필터 작업을 하고, 그림을 그리고, 친구들을 위해 요리하는 법을 배웠습니다.
OpenAI에서는 처음에는 $5의 무료 크레딧을 주지만, 이 과정에서 비용이 청구될 수 있습니다.
5. 응답 분석
4번 과정에서 말씀드렸듯이, 반환된 응답은 response 객체입니다. response 객체에는 응답 텍스트와 응답 텍스트의 source가 포함되어 있습니다. (원래 한줄로 뜨는데, 보기 불편하실까봐 위치에 맞게 줄바꿈 했습니다)
# get sources
print(response.source_nodes)
-------------------------------------------실행결과---------------------------------------------
[NodeWithScore(node=TextNode(id_='bb71b0ab-4ba7-48ea-9f5b-cffd4dc328a1',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='ecb74a39-6b03-4b0a-bf1c-3c99e1e7a6e6',
node_type=None,
metadata={},
hash='4c702b4df575421e1d1af4b1fd50511b226e0c9863dbfffeccb8b689b8448f35'),
<NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='48432c7d-028a-42c6-af6f-1cef53cf3a44',
node_type=None,
metadata={},
hash='d6c408ee1fbca650fb669214e6f32ffe363b658201d31c204e85a72edb71772f')},
hash='b4d0b960aa09e693f9dc0d50ef46a3d0bf5a8fb3ac9f3e4bcf438e326d17e0d8',
text='What I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.\n\nThe first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district\'s 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain\'s lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights.\n\nThe language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.\n\nI was puzzled by the 1401. I couldn\'t figure out what to do with it. And in retrospect there\'s not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn\'t have any data stored on punched cards. The only other option was to do things that didn\'t rely on any input, like calculate approximations of pi, but I didn\'t know enough math to do anything interesting of that type. So I\'m not surprised I can\'t remember any programs I wrote, because they can\'t have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn\'t. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager\'s expression made clear.\n\nWith microcomputers, everything changed. Now you could have a computer sitting right in front of you, on a desk, that could respond to your keystrokes as it was running instead of just churning through a stack of punch cards and then stopping. [1]\n\nThe first of my friends to get a microcomputer built it himself. It was sold as a kit by Heathkit. I remember vividly how impressed and envious I felt watching him sitting in front of it, typing programs right into the computer.\n\nComputers were expensive in those days and it took me years of nagging before I convinced my father to buy one, a TRS-80, in about 1980. The gold standard then was the Apple II, but a TRS-80 was good enough. This was when I really started programming. I wrote simple games, a program to predict how high my model rockets would fly, and a word processor that my father used to write at least one book. There was only room in memory for about 2 pages of text, so he\'d write 2 pages at a time and then print them out, but it was a lot better than a typewriter.\n\nThough I liked programming, I didn\'t plan to study it in college. In college I was going to study philosophy, which sounded much more powerful. It seemed, to my naive high school self, to be the study of the ultimate truths, compared to which the things studied in other fields would be mere domain knowledge. What I discovered when I got to college was that the other fields took up so much of the space of ideas that there wasn\'t much left for these supposed ultimate truths. All that seemed left for philosophy were edge cases that people in other fields felt could safely be ignored.\n\nI couldn\'t have put this into words when I was 18. All I knew at the time was that I kept taking philosophy courses and they kept being boring. So I decided to switch to AI.\n\nAI was in the air in the mid 1980s, but there were two things especially that made me want to work on it: a novel by Heinlein called The Moon is a Harsh Mistress, which featured an intelligent computer called Mike, and a PBS documentary that showed Terry Winograd using SHRDLU. I haven\'t tried rereading The',
start_char_idx=0,
end_char_idx=4050,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'),
score=0.8165804737384187),
NodeWithScore(node=TextNode(id_='abe61d8a-fd0e-4e0d-b95c-44d99448c9d9', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='ecb74a39-6b03-4b0a-bf1c-3c99e1e7a6e6', node_type=None, metadata={}, hash='4c702b4df575421e1d1af4b1fd50511b226e0c9863dbfffeccb8b689b8448f35'), <NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(node_id='8abc20bf-6fbb-40e4-abba-8989fdcdd0dd', node_type=None, metadata={}, hash='369d4b8408efce15403807dc303829bb8b79043c1ac241f75902d64e2f095a88'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='32ec5fc7-f904-455a-b9e7-2708189b6a4f', node_type=None, metadata={}, hash='3f85a689b50d492e5189934a36d48819c99fa126579aebc31931f0896803bb6f')}, hash='38f9861527b45032d1cb7b872389cb52b6ca601f22f3cfa8d2c9d325b80c65b9', text="which I'd created years before using Viaweb but had never used for anything. In one day it got 30,000 page views. What on earth had happened? The referring urls showed that someone had posted it on Slashdot. [10]\n\nWow, I thought, there's an audience. If I write something and put it on the web, anyone can read it. That may seem obvious now, but it was surprising then. In the print era there was a narrow channel to readers, guarded by fierce monsters known as editors. The only way to get an audience for anything you wrote was to get it published as a book, or in a newspaper or magazine. Now anyone could publish anything.\n\nThis had been possible in principle since 1993, but not many people had realized it yet. I had been intimately involved with building the infrastructure of the web for most of that time, and a writer as well, and it had taken me 8 years to realize it. Even then it took me several years to understand the implications. It meant there would be a whole new generation of essays. [11]\n\nIn the print era, the channel for publishing essays had been vanishingly small. Except for a few officially anointed thinkers who went to the right parties in New York, the only people allowed to publish essays were specialists writing about their specialties. There were so many essays that had never been written, because there had been no way to publish them. Now they could be, and I was going to write them. [12]\n\nI've worked on several different things, but to the extent there was a turning point where I figured out what to work on, it was when I started publishing essays online. From then on I knew that whatever else I did, I'd always write essays too.\n\nI knew that online essays would be a marginal medium at first. Socially they'd seem more like rants posted by nutjobs on their GeoCities sites than the genteel and beautifully typeset compositions published in The New Yorker. But by this point I knew enough to find that encouraging instead of discouraging.\n\nOne of the most conspicuous patterns I've noticed in my life is how well it has worked, for me at least, to work on things that weren't prestigious. Still life has always been the least prestigious form of painting. Viaweb and Y Combinator both seemed lame when we started them. I still get the glassy eye from strangers when they ask what I'm writing, and I explain that it's an essay I'm going to publish on my web site. Even Lisp, though prestigious intellectually in something like the way Latin is, also seems about as hip.\n\nIt's not that unprestigious types of work are good per se. But when you find yourself drawn to some kind of work despite its current lack of prestige, it's a sign both that there's something real to be discovered there, and that you have the right kind of motives. Impure motives are a big danger for the ambitious. If anything is going to lead you astray, it will be the desire to impress people. So while working on things that aren't prestigious doesn't guarantee you're on the right track, it at least guarantees you're not on the most common type of wrong one.\n\nOver the next several years I wrote lots of essays about all kinds of different topics. O'Reilly reprinted a collection of them as a book, called Hackers & Painters after one of the essays in it. I also worked on spam filters, and did some more painting. I used to have dinners for a group of friends every thursday night, which taught me how to cook for groups. And I bought another building in Cambridge, a former candy factory (and later, twas said, porn studio), to use as an office.\n\nOne night in October 2003 there was a big party at my house. It was a clever idea of my friend Maria Daniels, who was one of the thursday diners. Three separate hosts would all invite their friends to one party. So for every guest, two thirds of the other guests would be people they didn't know but would probably like. One of the guests was someone I didn't know but would turn out to like a lot: a woman called Jessica Livingston.", start_char_idx=43926, end_char_idx=47930, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), score=0.8140936748970858)]총 2개의 source_nodes가 나타나고, text 부분에는 참조한 내용이 들어있는 것을 확인할 수 있습니다.
score는 유사도를 나타내며 높을 수록 더 가까운 관계에 있다는 것을 의미합니다.
여기에서의 Doc ID는 nodes에서의 id_와 동일한 값입니다.
아래 코드는 간단하게 nodes의 id_들을 출력하는 코드이고, NodeWithScore에서의 id_값과 동일한지 비교해보실 수 있습니다.
for i in range(len(nodes)):
print(nodes[i].id_)
---------------------------------------------------------------------------------------------
bb71b0ab-4ba7-48ea-9f5b-cffd4dc328a1 # 1st
48432c7d-028a-42c6-af6f-1cef53cf3a44
488f1f8e-a9a6-4bc0-8022-5310880e9b0e
d54356af-d641-4693-8486-cfbfc5161af7
190e84a2-7729-4272-ba69-f4d0acdcf6d9
a74a9813-845a-409c-af22-050a4f42b8f8
a55087b4-ab88-443d-8223-07df2db3e8a5
1eeca4b2-47d4-4aad-a62e-72d7e7ac7832
3964a424-ac4d-4cb0-a9f3-c12c93662f6d
d6ed2cf3-8b79-4b5f-a6f5-286b7ef35627
8abc20bf-6fbb-40e4-abba-8989fdcdd0dd
abe61d8a-fd0e-4e0d-b95c-44d99448c9d9 # 2nd
32ec5fc7-f904-455a-b9e7-2708189b6a4f
ddde4bfd-dd5c-427a-9763-9d29b4af96fd
28c65e1d-d105-419c-b607-669cb39cb508
70905600-1581-4c26-a98c-c5e132ae3558
8ffd3cfb-a294-472a-9884-25d37371b48c
437c634e-becc-4f21-8bee-dad6dcc1c1ed
19e532e3-6685-45e0-b4a6-81b6186dac2a
396a4845-1f49-44e9-9e94-beefd95034d9'IT KNOWLEDGE' 카테고리의 다른 글
| HTTP Request, Response 구조 (0) | 2023.07.17 |
|---|---|
| 캐시와 레지스터 (0) | 2023.07.11 |
| Rancher로 Kubernetes 환경 구축하기 - 설치 및 개요 (0) | 2023.07.06 |
| Kafka (0) | 2023.06.27 |
| LlamaIndex 설치 & OpenAI API 키 발급 방법 (0) | 2023.06.23 |




댓글