베하~ 반갑습니다!!
인사통의 BTC_김회장, 최총무입니다!!

오늘은 Airflow Dag를 사용해서 Cloud Dataproc를 조작해보도록 하겠습니다!!
Dataproc은 처음 다루는 내용이니 개요부터 차근차근 진행하겠습니다~

개요
- Dataproc이란?
- Airflow Dag를 활용한 Dataproc 사용
1. Dataproc이란?
Dataproc은 일괄 처리, 쿼리, 스트리밍, 머신 러닝에 오픈소스 데이터 도구를 활용할 수 있는 관리형 Spark 및 Hadoop 서비스라고 Docs에 설명되어 있습니다. 간단히 말씀드리면 손쉽게 용도에 맞는 오픈소스 도구를 포함한 클러스터를 생성 및 관리해주는 서비스라고 생각하시면 될것 같습니다!

Data proc의 대표적인 장점은 다음과 같습니다.
1. 비용 절감 가능 - 분당 과금정책을 가지고 있어 원하는 시간만큼 연산을 실행 후 클러스터를 내리면 추가 비용이 따로 없습니다.
2. 빠른 환경 구성 - 생성 과정에서 설정한 오픈소스 도구를 설치하기에 편리하고 빠릅니다.
3. 서비스 통합성 - GCP의 다른 서비스와 기본적으로 통합되어 호환에 용이합니다.
즉,Data proc은 설치과정에서 원하는 오픈소스를 지정하여 클러스터를 생성할 수 있어 시간을 절약할 수 있고
특히나 서버리스로 생성할 수 있어서 간단히 테스트 환경을 구성하는 경우 유용합니다.
더욱 자세한 Dataproc의 정보가 궁금하시다면 이전에 작성된 포스트를 공유드리겠습니다~
Cloud Dataproc
첫번째. Hadoop Ecosystem (1) Apache Hadoop 분산 환경의 병렬 처리 프레임워크로, 크게 보면 분산 파일 시스템인 HDFS(Hadoop Distributed File System)와 데이터 처리를 위한 MapReduce 프레임워크로 구성 여러 대의
btcd.tistory.com
2. Airflow Dag를 활용한 Dataproc 사용
함께 차근차근 진행해보시죠!! 사전 준비물은 Airflow가 설치된 환경입니다!!
혹시 방법을 모른다면 Airflow 설치 및 DAG 생성하기 포스팅을 먼저 따라해주세요~
[Airflow] Airflow 설치 및 DAG 생성하기
베하 ! 문땅훈과 루피입니다!! 오늘은 Airflow 실습을 해보겠습니다. 설치 및 DAG 생성까지 해보도록 하겠습니다. 개요 Airflow pip로 실행 Airflow Docker image 생성 후 실행 Airflow 실행 및 접속을 위해서 총
btcd.tistory.com
Airflow까지 준비되었다면 함께 Dataproc을 생성해보시죠!!
이번엔 실습이니 최대한 간단히 만들겠습니다.

아마 VM이나 GKE를 자주 사용하신 분이라면 어렵지 않게 생성하실 수 있을거에요.
특이사항이라면 아래 선택적 구성요소를 통해 오픈소스 데이터 도구를 사전 선택하여 설치할 수 있다는 점 입니다!!


또한 Dataproc에는 스테이징 버킷이라는 선택지가 있습니다.

스테이징 버킷은 Google Cloud의 Dataproc 서비스에서 임시 데이터를 저장하는 데 사용됩니다.
Dataproc 클러스터를 생성하거나 작업을 제출할 때, Dataproc는 이 버킷을 사용하여 다양한 시스템 파일, 로그, 결과 데이터 등을 저장합니다!!
이외에는 특이사항 없으니 각자 상황에 맞게 설정해주세요!!

생성 되었다면 원래는 Dataproc 상단의 작업 제출을 통해 작업을 선택해주어야 하지만 저희는 이걸 Airflow를 통해 진행하겠습니다.
VM 인스턴스를 확인하시면 아마 Dataproc 생성과 동시에 vm이 생겨있을거에요~
해당 VM에 있는 예제를 통해 진행할테니 접속 진행해볼까요?
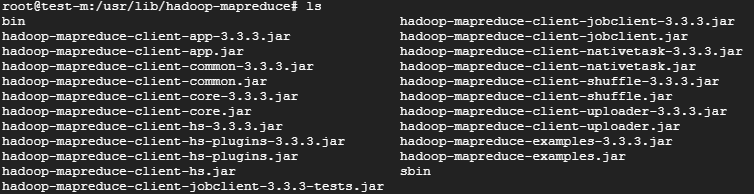
/usr/lib/hadoop-mapreduce 내부에 있는 hadoop-mapreduce-examples.jar를 활용할겁니다.
hadoop-mapreduce-examples.jar는 Hadoop MapReduce 프레임워크에 포함된 예제 애플리케이션 모음이라고 보시면 됩니다!!
해당 VM은 종료하고 AIRFLOW DAG를 만들어볼까요?
예제 코드는 다음과 같습니다!!
from datetime import datetime
from airflow import DAG
from airflow.providers.google.cloud.operators.dataproc import DataprocSubmitJobOperator
# DAG 설정
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 8, 16),
'retries': 0,
}
today = datetime.today().strftime('%Y-%m-%d')
with DAG('tutorial',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval='0 0 * * *',
) as dag:
run_dataproc = DataprocSubmitJobOperator(
task_id='run_dataproc_job',
region='{REGION명}',
project_id='{프로젝트 ID}',
job={
'placement': {
'cluster_name': 'test'
},
'hadoop_job': {
'main_jar_file_uri': 'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar',
'args': [
"wordcount",
"gs://{버킷명}/word.txt",
f"gs://{버킷명}/output/{today}/"
]
}
}
)간단히 설명을 드리면 hadoop vm내부의 file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar를 참조하여
word.txt 의 파일 속 각 단어의 갯수를 count 하여 output/{today}/ 로 출력합니다.
이대로 실행해볼까요?
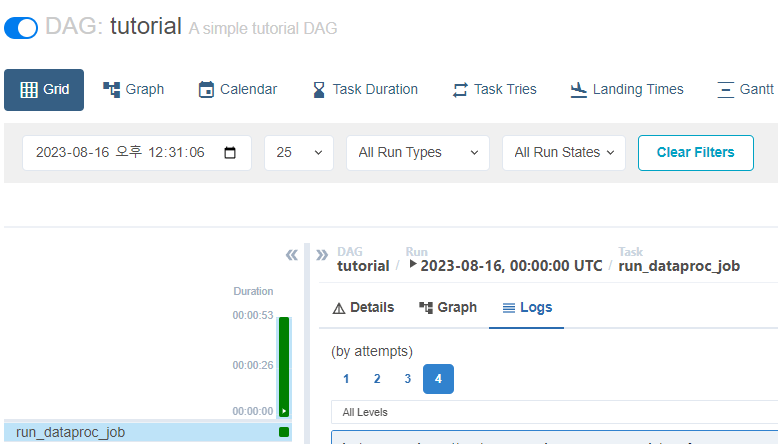
이상 없이 success되는것을 확인할 수 있습니다!!
혹시 이곳에서 에러가 난다면 방화벽이나 파일 생성 권한등을 살펴봐주세요~
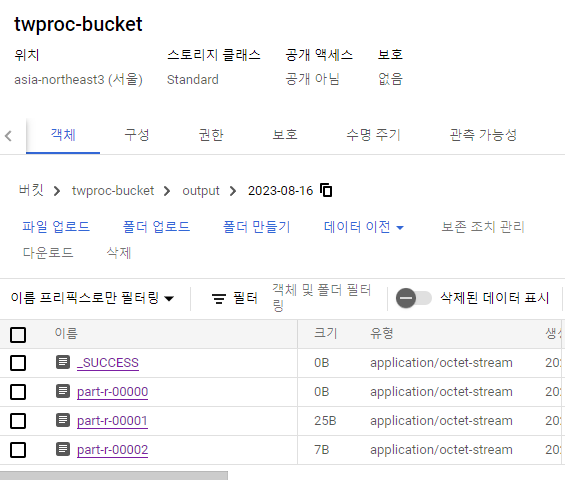
목적지 디렉토리에 가면 success와 함께 word count의 결과물이 저장되어 있습니다!!

작업 파일이 여러개로 나누어진 이유는 hadoop의 노드가 병렬처리로 작업을 처리했기 때문이죠!!
이상으로 오늘 실습을 마치겠습니다~
Dataproc을 통해 작업을 하려면 Submit job이라는 작업이 필요합니다.
하지만 Airflow를 통해 DataprocSubmitJobOperator로 이 Submit job을 자동화 할 수 있으니 편리하죠?
일정 시간마다 자동으로 Job을 제출해서 실행시켜 준답니다.

그럼 다음번에도 더욱 유용한 정보를 알려드리러 오겠습니다!!
모두 베빠!!
'Database' 카테고리의 다른 글
| SQL과 NoSQL 데이터베이스 (0) | 2023.08.18 |
|---|---|
| Airflow : API를 활용한 Image 다운로드 (0) | 2023.08.17 |
| [Airflow] Decorator (0) | 2023.08.07 |
| [Airflow] Airflow CLI 명령어 (0) | 2023.07.24 |
| 빅쿼리 INFORMATION_SCHEMA (0) | 2023.07.21 |


댓글