탑신병자 듀오 팀 티모입니다.
오늘은 AWS 기반 실시간 데이터 파이프라인을 이어서 구축해보겠습니다.

실습 과정입니다.
- Kinesis Data Streams : 지속적으로 생산되는 실시간 IoT 로그들을 Kinesis Data Streams 내 Buffer Storage에 수집합니다. 수집된 데이터들은 Shard에 저장되며 Consumer들은 Shard에 저장된 데이터들을 가져가 사용합니다.
- Glue Streaming : ETL 서비스인 AWS Glue을 통해 Kinesis Data Streams에 쌓이는 실시간 데이터를 처리합니다.
처리가 완료된 데이터들은 Amazon S3에 저장합니다. - Glue Data Catalog : 실시간 유입되는 데이터들을 처리하기 위해 데이터의 스키마 형식을 Glue Data Catalog에 저장합니다. Glue Streaming(2)에서는 사전에 정의된 스키마를 기준으로 데이터를 처리합니다.
- Reference Data(S3) : Glue Streaming(2)에서 실시간으로 유입되는 데이터들을 Join하기 위한 Reference 데이터를 S3에 저장합니다
- Glue Crawler / Glue Data Catalog : 2~4 과정을 거쳐 최종적으로 S3에 저장된 데이터들을 스캔하여 데이터 카탈로그를 생성, 하나 이상의 테이블을 생성합니다. 여기서 정의된 데이터 카탈로그를 기준으로 Athena를 통해 데이터를 분석합니다.
- Amazon Athena : Glue Data Catalog를 참조하여 S3의 데이터에 대해 SQL 기반의 분석을 진행합니다.
이를 통해 ETL이 완료된 데이터를 간편하게 데이터를 분석 할 수 있습니다. - Amazon Quicksight : Athena(6)를 통해 분석한 결과들을 다양한 대시보드 기능을 통해 시각화하여 사용자가 원하는 방식으로 데이터 분석 결과를 보여줍니다.
데이터 처리를 위한 사전 작업을 진행했고, streaming job을 생성하는 것으로 이어서 진행합니다. (2. Glue Streaming)
Glue > ETL jobs 선택 후 Visual with blank canvas로 생성합니다.

Glue Job을 시각화로 생성하는 메뉴로 이동했다면, 우선 kinesis부터 설정합니다.
- Amazon Kinesis Source : Data Catalog table
- Database : iotstream
- Table : iot-stream-raw
- Detect schema inactive(체크 해제)


Kinesis로 수집한 데이터들을 Reference 데이터와 조인하기 위해 스키마 설정을 변경해줍니다.
add nodes(좌측 위 +)를 눌러 Transforms > Change Schema을 선택합니다.
- Node Parent : Amazon Kinesis
- Change Schema : track_id(Int -> String)


다음은 Kinesis로부터 수집한 데이터들을 Join하기 위한 Reference Data를 추가합니다.
sources > AWS Glue Data Catalog를 선택합니다.
- Database : iotstream
- Table : reference


지금까지 생성한 테이블을 Join합니다.
Transforms > Join을 선택합니다.
- Node Parent : AWS Glue Data Catalog, Change Schema
- Join Condition : track_id = track_id

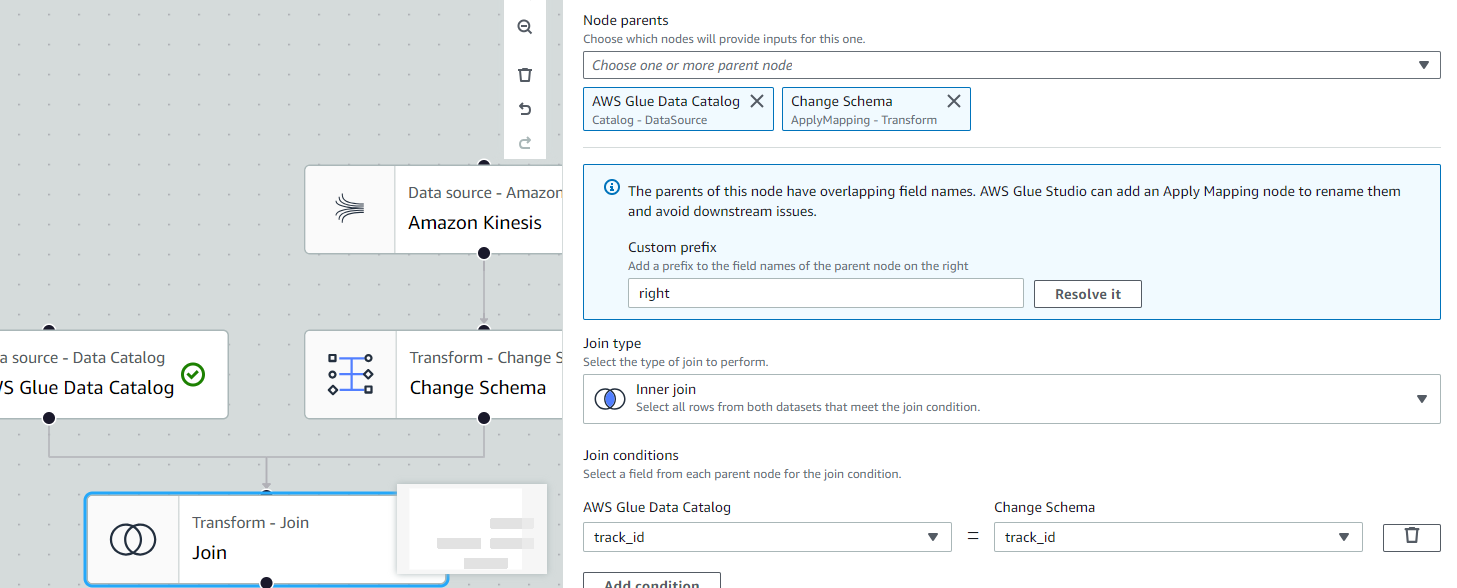
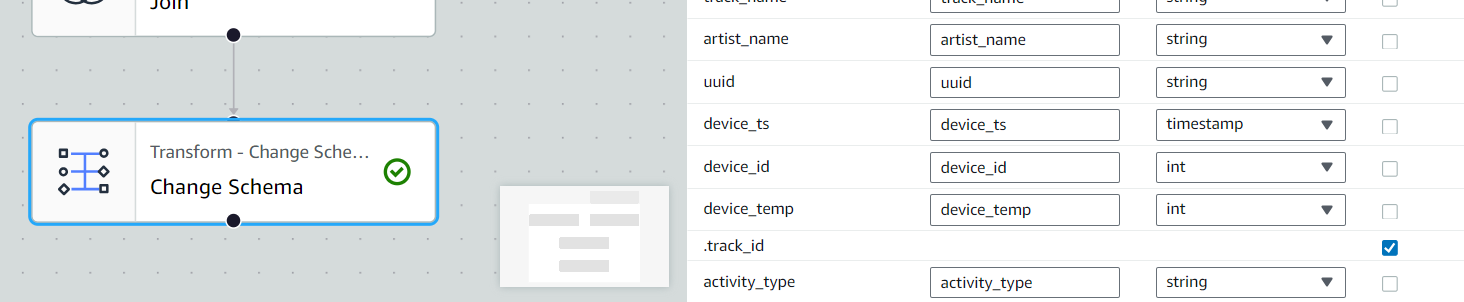
Join까지 완료한 테이블을 추가로 Change Schema 작업을 진행하여 특정 레코드 값을 제거합니다.
Transforms > Change Schema을 선택합니다.
- Change Schema : .track_id Drop(체크)
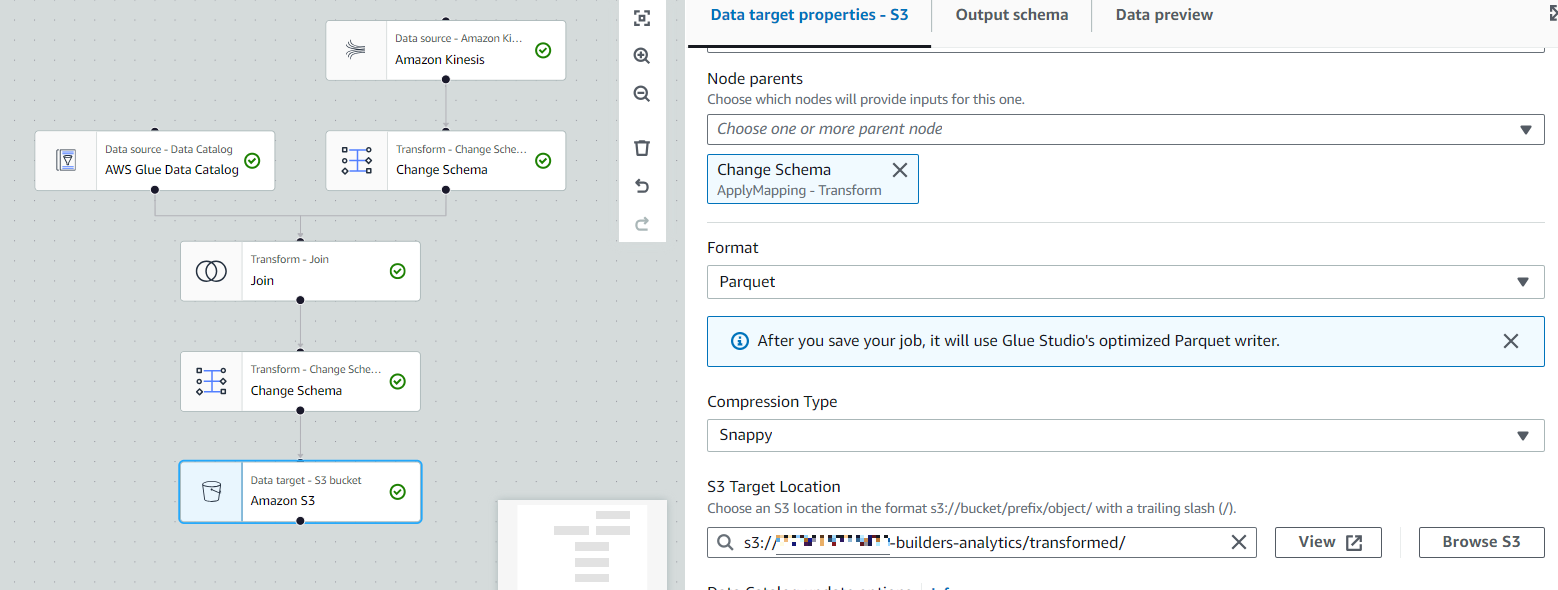
마지막으로 지금까지 작업한 데이터들을 S3에 저장하기 위한 과정을 진행합니다.
기존의 JSON 타입의 데이터들을 빠른 데이터 분석을 위한 Parquet 형식으로 변환 및 압축하는 작업도 함께 진행합니다. Targets > Amazon S3를 선택합니다.
- Node Parent : Change Schema(.track_id Drop한 JOIN이 완료된 테이블)
- Format : Parquet
- Compression Type : Snappy
- S3 Target Location : {AWS Account}-builders-analytics/transformed/

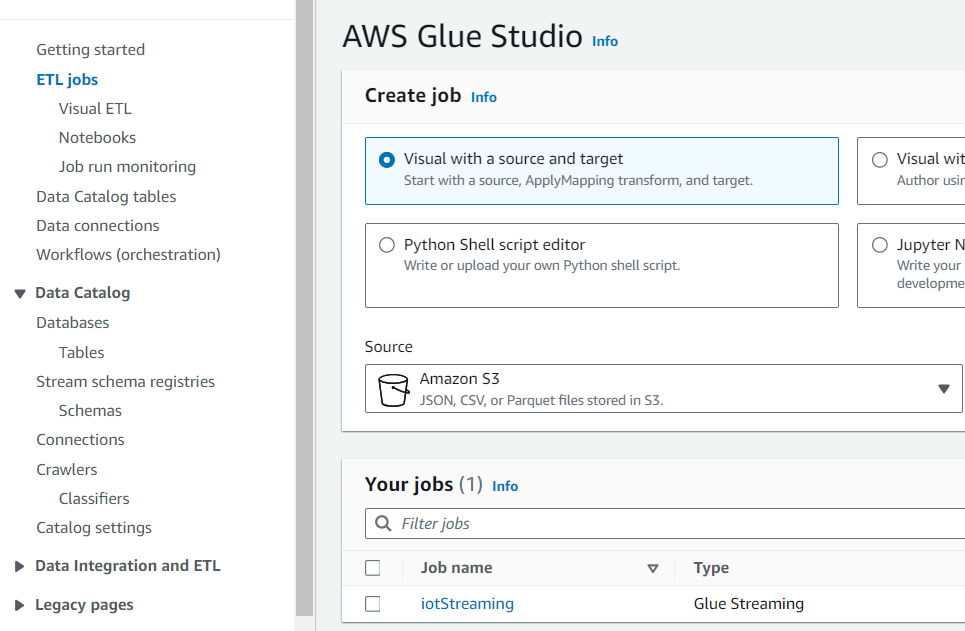
Job details로 이동하여 Job Name과 IAM 그리고 Worker Node의 수를 지정한 뒤 save합니다.
- Job Name : iotStreaming
- IAM : Glueadmin
- Worker Type : G 0.25X
- Requested number of workers = 2


ETL jobs로 돌아가 확인합니다.
이제 Streaming Job을 실행해봅니다.
먼저 Kinesis Data Generator로 이동하여 실시간 데이터를 Kinesis로 전송합니다.
전송 대상은 iot-data-stream-1입니다. 데이터 전송 후 iotStreaming을 실행합니다.
Job run monitroing 메뉴를 통해서 Glue Streaming Job의 상태를 확인 할 수 있습니다.
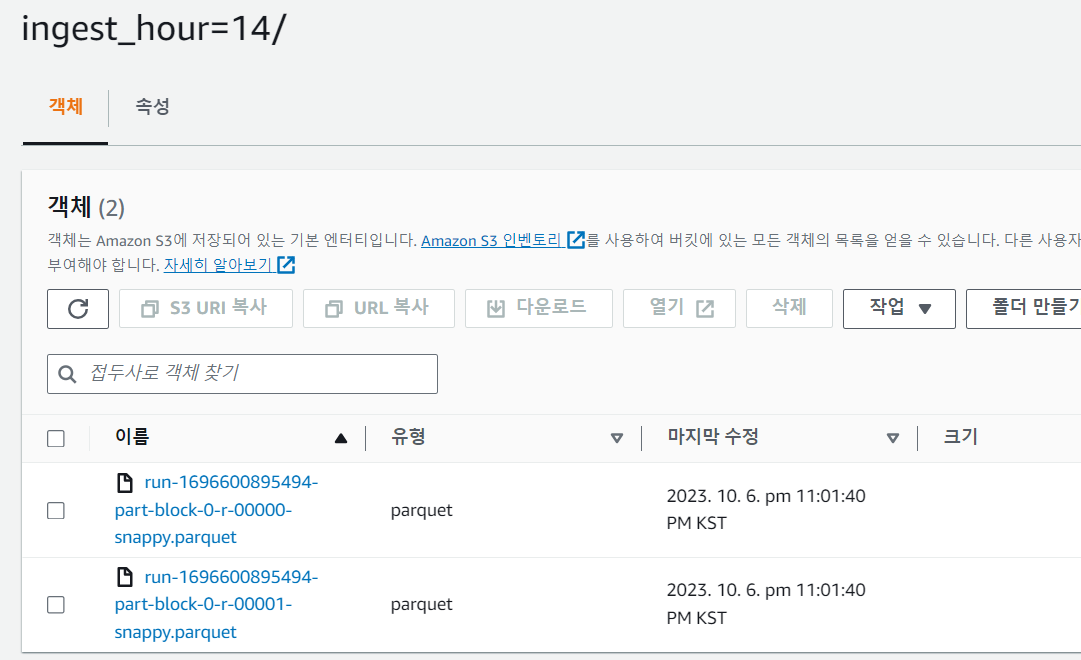
Amazon S3에서 ETL이 완료된 데이터들이 정상적으로 저장된 것을 확인할 수 있습니다.
경로는 builders-analytics/transformed/ingest_(year)/ingest_(month)/ingest_(day)/ingest_(hour)/ 입니다.
여기까지가 Glue Streaming Job을 생성하고 실행하는 과정입니다.
실습이 잘 진행된 것을 확인한 뒤에는 job을 중지하고 데이터 전송 역시 중지합니다.
다음은 위 실습으로 ETL 작업이 완료된 데이터를 대상으로 SQL 기반의 데이터 분석을 해보겠습니다.
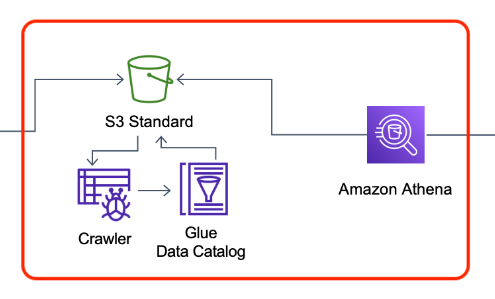
Glue Crawler를 이용 S3에 저장된 데이터를 스캔하고 데이터 스키마를 정의합니다.
Crawler를 생성합니다.
- Crawler Name : Transformed
- Data Source : S3
- S3 path : {AWS Account ID}-builders-analytics/transformed/
- IAM Role : glueadmin
- Target database : iotstream

Crwaler 실행 후 Data Catalog -> Database -> Tables로 이동, transformed의 Table data를 클릭합니다.
Athena로 이동한 뒤, 쿼리문을 수정해 실행해봅니다.
SELECT * FROM "AwsDataCatalog"."iotstream"."transformed" limit 10;쿼리 결과에서 track_name과 artist_name이 추가 된 것을 확인할 수 있습니다.
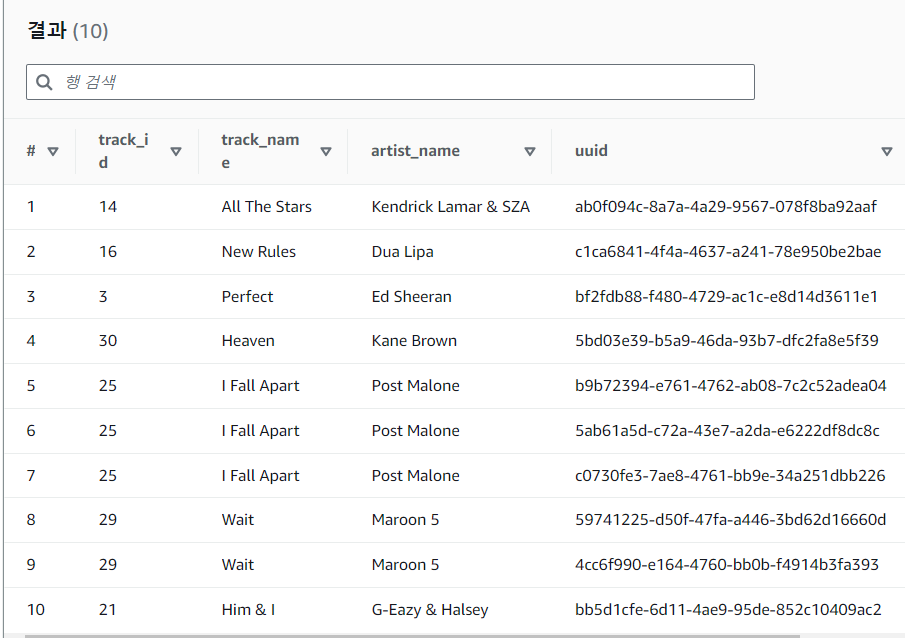
Athena를 통하여 데이터 분석을 실행할 수 있습니다.
새로운 쿼리를 실행하기 위해 우측의 + 버튼을 클릭하여 새로운 쿼리 화면을 생성합니다.
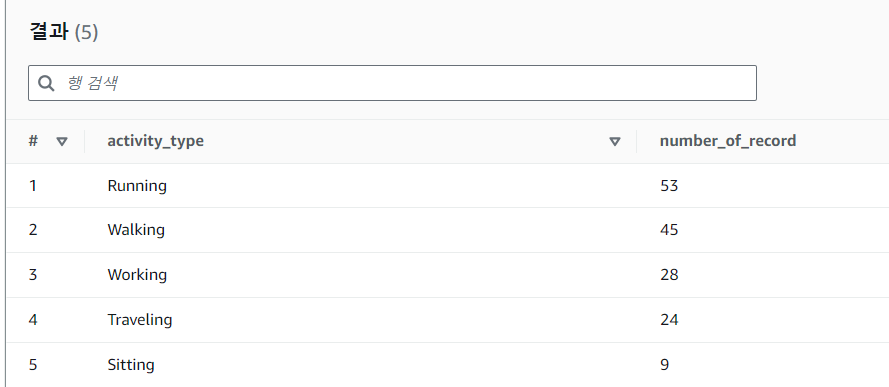
온도가 40도 이상인 디바이스들의 Activity_type과 수를 계산하고 이를 Table1 이라는 테이블에 데이터를 적재합니다.
아래 쿼리 실행 시 external_location의 {AWS Account ID}에 개인 계정 ID를 넣어 수정합니다.
CREATE TABLE "iotstream"."tab1"
WITH(
external_location = 's3://{AWS Account ID}-builders-analytics-athena/tab1',
format = 'Parquet'
)
AS SELECT "activity_type", count("device_id") as Number_of_Record
FROM "AwsDataCatalog"."iotstream"."transformed"
where "iotstream"."transformed"."device_temp" >= 40
GROUP BY "activity_type"
ORDER BY "number_of_record" desc; 위 쿼리를 실행 했을때 tab1 이라는 테이블이 생성 된 것을 확인할 수 있으며,
tab1을 클릭 후 테이블 미리보기를 클릭하여 데이터를 조회 할 수 있습니다.
다음 시간에는 Amazon Quicksight를 통해 시각화하는 과정을 이어서 진행하겠습니다.
감사합니다.
'CSP (Cloud Service Provider) > AWS' 카테고리의 다른 글
| Amazon VPC Lattice (1) | 2023.10.11 |
|---|---|
| [AWS] Trusted Advisor (0) | 2023.10.10 |
| [AWS] AWS Amplify (0) | 2023.10.05 |
| [AWS] 스토리지 관련 다양한 서비스 (1) | 2023.10.04 |
| [AWS] CloudShell (0) | 2023.10.02 |




댓글