안녕하세요!!
24/365입니다!
오늘은 'LRU 알고리즘'에 대해서 알아보도록 하겠습니다!
목차
1. LRU 알고리즘이란?
2. 어디에 사용되나요?
3. 데이터 버퍼 캐시
4. LRU 알고리즘의 원리
LRU 알고리즘이란?
'LRU 알고리즘'은
Least Rencently Used의 약어입니다
인터넷에 검색해보면 아래와 같은 정의를 많이 볼 수 있습니다.
'가장 오랫동안 참조되지 않은 페이지를 교체하는 방식'
음... 잘 이해가 안 가는데요..

쉽게 말해
'최근에 많이 참조된 페이지를 계속 앞에 위치시키는 것을 말합니다'
'자주 쓰는 것은 앞으로도 사용될 확률이 높고,
그 반대의 경우는 사용될 확률이 낮다'
라는 가설에 의해 만들어졌다고 합니다!
어디에 사용되나요?
그렇다면.. LRU 알고리즘은 어디에 사용될까요??
저희는 DB에 대한 공부를 하고 있으니
DB에 사용되는 LRU 알고리즘에 대해서 알아보도록 하겠습니다!
DB에서 LRU 알고리즘은 공유 메모리(SGA) 중
'데이터 버퍼 캐시'에서 사용이 됩니다.
https://btcd.tistory.com/60?category=927631
[Oracle]메모리 구조
안녕하세요! BTC 24/365입니다!! 오늘부터는 특정 DB에 관련된 내용을 전달해볼 예정이며, 이번 게시글에서는 DB 시장 점유율 1위의 'Oracle'에 대해서 알아보도록 하겠습니다!! 목차 1. PGA 2. SGA 3. Backgro
btcd.tistory.com
위 오라클 메모리 구조에 대한 설명을
정리해둔 게시글을 참조하시면 이해가 쉬울 것 같습니다!!
보통은 user가 data를 요청하면
먼저, 해당 data를 데이터 버퍼 캐시(메모리)에서 search를 합니다.
만일, 메모리에 data가 없다면 디스크에서 data를 찾아오죠
이때 요청한 data가 메모리에 존재하고 있다면
디스크에서 data를 가져오는 것보다 더욱 빠르게
data를 user에게 전달할 수가 있겠죠?!
그렇다면 메모리에 data를 존재시키는 기준이 뭘까요??
바로 'LRU 알고리즘'입니다!
LRU 알고리즘에 의해서 가장 오랫동안
참조되지 않은 data는 캐시에서 사라지게 됩니다
데이터 버퍼 캐시
앞서 설명한 것과 같이 'LRU 알고리즘'을 이해하려면
데이터 버퍼 캐시에 대한 이해가 필요합니다!!
'데이터 버퍼 캐시'는 데이터 블록이 존재하는 공간입니다.
user가 data를 요청하면 데이터 버퍼 캐시에서 data를 찾습니다.
하지만, 데이터 버퍼 캐시에 원하는 data가 없다면
data를 저장하는 디스크에서 data를 찾아
데이터 버퍼 캐시에 올려 data를 read 하게 되죠!
LRU 알고리즘 작동 원리
앞서 LRU 알고리즘이 어떠한 알고리즘인지 알아보았습니다!
그렇다면 어떠한 원리로 LRU 알고리즘이 작동될까요??
그림으로 이해해볼까요??
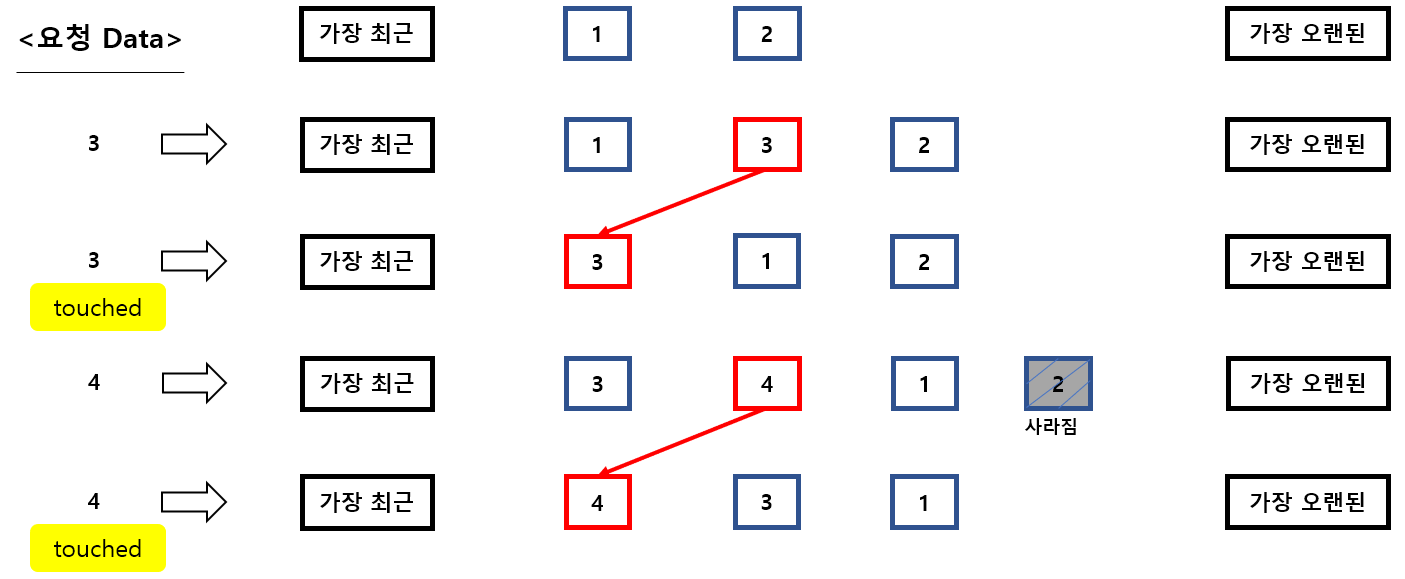
1. 우선 user가 '3'을 요청하면 '1', '2' 사이에서 가장 앞으로 위치하게 됩니다.
(여기서 1,2는 기존에 남아 있던 data를 지칭 합니다.)
2. 동일한 원리로 '4'를 요청하면 또 다시 가장 앞으로 위치합니다.
3. 여기서 가장 중요한 것은 요청을 받지 않은 번호는 점점 뒤로 밀리게 되고,
결국에는 '2'처럼 메모리 버퍼 캐시에서 사라지게 되는거죠
(실제로 data가 사라지는 것은 아니며, 디스크로 저장이 됩니다)
오늘은 LRU 알고리즘에 대해서 알아 보았습니다!
DB를 알려면 꼭 알아야 하는 이론은 아니지만
한번쯤은 알고 넘어가면 DB공부 & 업무 하실 때
도움이 될 거라 생각합니다!
'Database' 카테고리의 다른 글
| [24/365] 쿼리 Select & Update 과정(1) (0) | 2022.05.23 |
|---|---|
| 이상 현상(Anomaly)이란? (0) | 2022.05.13 |
| [24/365] Oracle DB 논리적 구조 (0) | 2022.05.09 |
| E-R 다이어그램 (0) | 2022.05.04 |
| [24/365] 논리적 물리적 구조 (0) | 2022.05.02 |




댓글