첫번째 개요
(1) 관련 서비스 소개
ⓐ BigQuery
몇 초만에 대규모 데이터를 쿼리할 수 있는 관계형 클라우드 데이터베이스
[GCP in Action] CH 19. BigQuery-①
https://blog.naver.com/ohn-lab/222601565238
[GCP in Action] CH 19. BigQuery-②
https://blog.naver.com/ohn-lab/222605131452
ⓑ Dataflow
Apache Beam에서 사용 가능한 여러 옵션 중 하나로, 완전 관리형 파이프라인 러너
* Apache Beam
ETL, 배치 및 스트림 처리를 포함한 데이터 처리 파이프 라인을 정의하고 실행하기위한 오픈 소스 통합 프로그래밍 모델
[GCP in Action] CH 20. Cloud Dataflow
https://blog.naver.com/ohn-lab/222619135822
ⓒ Cloud Storage
(2) 실습 목표
BigQuery에서 이용가능한 데이터셋을 이용해 데이터를 수집하고 처리하는 데이터 파이프라인을 생성
두번째 준비
(1) Ensure that the Dataflow API is successfully enabled
실습 시 이용할 서비스들 간의 통신을 위해 APIs & Services 에서 Dataflow API에 대한 API 활성화
필히 비활성화 후 다시 활성화 시킴으로써 재연결을 해줘야 함
재연결을 해주지 않으면 파이프라인이 생성되지 않을 수도 있음
(2) Download the starter code
GCP Github로부터 Dataflow 생성용 파이썬 코드 파일을 복사
(3) Create Cloud Storage Bucket and Copy Files to Your Bucket
실습에 사용할 CSV 형식의 데이터 파일을 저장하기 위한 Cloud Storage 버킷 생성
GCP Github로부터 데이터 파일을 Cloud Storage의 버킷으로 복사
※ 퀵랩 진행 이전 또는 이후로 파이썬 코드나 데이터 파일을 확인하고 싶다면 Cloud shell에서 아래의 명령어를 실행
export PROJECT=<YOUR-PROJECT-ID>
gcloud config set project $PROJECT
gsutil mb -c regional -l us-central1 gs://$PROJECT
gsutil -m cp -R gs://spls/gsp290/dataflow-python-examples gs://$PROJECT/
gsutil cp gs://spls/gsp290/data_files/usa_names.csv gs://$PROJECT/data_files/
gsutil cp gs://spls/gsp290/data_files/head_usa_names.csv gs://$PROJECT/data_files/
파이썬 코드 파일의 경우 Cloud Storage 버킷에서 아래의 경로로 접근하여 확인
<YOUR-PROJECT-ID>/dataflow-python-examples/dataflow_python_examples
(4) Create the BigQuery Dataset
결과 데이터를 취합하기 위해 BigQuery에 데이터셋 생성
세번째 데이터 파이프라인
(1) Build a Dataflow Pipeline
Dataflow 파이프라인 생성
(2) Data Ingestion
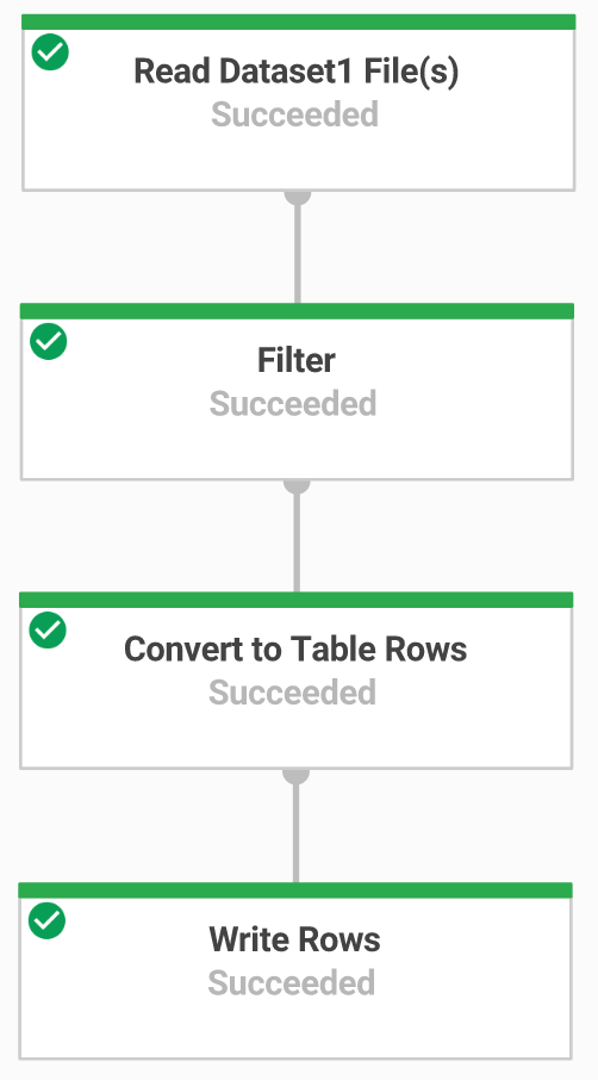
data_ingestion.py : 아래 과정에 대한 Dataflow 파이프라인을 생성하는 코드
Ingest the files from Cloud Storage.
Filter out the header row in the files.
Convert the lines read to dictionary objects.
Output the rows to BigQuery.
DataflowRunner를 이용해 생성된 파이프라인을 실행
BigQuery의 lake 프로젝트에 usa_names 테이블이 생성되고 여기에 결과 데이터가 저장됨
(3) Data Transformation
data_transformation.py : 아래 과정에 대한 Dataflow 파이프라인을 생성하는 코드
Ingest the files from Cloud Storage.
Convert the lines read to dictionary objects.
Transform the data which contains the year to a format BigQuery understands as a date.
Output the rows to BigQuery.
DataflowRunner를 이용해 생성된 파이프라인을 실행
BigQuery의 lake 프로젝트에 usa_names_transformed 테이블이 생성되고 여기에 결과 데이터가 저장됨
(4) Data Enrichment
data_enrichment.py : 아래 과정에 대한 Dataflow 파이프라인을 생성하는 코드
Ingest the files from Cloud Storage
Filter out the header row in the files
Convert the lines read to dictionary objects
Output the rows to BigQuery
이 과정에선 제공된 파이썬 코드를 일부 수정
데이터를 디코딩 하는 부분이 제외됨
values = [x.decode('utf8') for x in csv_row]
▼
values = [x for x in csv_row]
DataflowRunner를 이용해 생성된 파이프라인을 실행
BigQuery의 lake 프로젝트에 usa_names_enriched 테이블이 생성되고 여기에 결과 데이터가 저장됨
(5) Data lake to Mart
data_lake_to_mart.py : 아래 과정에 대한 Dataflow 파이프라인을 생성하는 코드
Ingest files from 2 BigQuery sources
Join the 2 data sources
Filter out the header row in the files
Convert the lines read to dictionary objects
Output the rows to BigQuery
DataflowRunner를 이용해 생성된 파이프라인을 실행
BigQuery의 lake 프로젝트에 orders_denormalized_sideinput 테이블이 생성되고 여기에 결과 데이터가 저장됨
'CSP (Cloud Service Provider) > GCP' 카테고리의 다른 글
| [Google Cloud Platform] GCP 스토리지, 컨테이너 (0) | 2022.05.20 |
|---|---|
| GKE로 배포 관리하기 (2)Canary 배포 (0) | 2022.05.20 |
| [Google Cloud Platform] Google Compute Engine, GCE (0) | 2022.05.13 |
| [GCP] 부하 분산기 (0) | 2022.05.13 |
| GKE로 배포 관리하기 (1)순차적 업데이트 (0) | 2022.05.13 |




댓글