베하 !
안녕하세요! 벌써 연말이 다가왔어요!! 날씨도 너무 추워졌는데
다들 감기예방하고 계신가요 !!
저는 최근에 자기 전 생강차를 한 잔 마시고 자는 루틴이 생겼는데
꽤 ,, 나름,, 감기에 안걸리고 건강하네요?
생강차 추천 드립니다 감 기 예 방

최근 S3 Access Log 또는 ELB Access Log를 분석해서 뭔가 인사이트나 장애원인 등을
확인하고자 하는 요청이 많았던 것 같습니다.
예를 들어, ELB 로그 중 요청 도메인 별로 일일 몇개정도가 요청되는지 ?
아니면 S3에서 GET 요청으로 다운로드 되는 시간과 건수는 얼마나 되는지 등?
다들 데이터를 활용해서 장애 예방이나, 인사이트 도출을 하시는구나 하고 많이 와닿았습니다.
그래서 S3 Access 로그 중 시간별 GET 요청 수를 통계로 보여주는 분석을 시도해보았습니다!
정말 간단한 실습이지만, Athena를 안써 본 병아리 입장에서는 이것 또한 배움의 장이었던 것으로 ,,,
그럼 지금 바로 가보겠습니다 !!!

AWS Athena란?
AWS Athena는 클라우드 기반의 쿼리 서비스로, Amazon S3에 저장된 데이터를 손쉽게 분석할 수 있는 도구입니다. Athena를 사용하면 SQL을 활용하여 S3에 저장된 데이터를 쿼리하고 분석할 수 있습니다.
이는 데이터 웨어하우스나 데이터베이스를 설정하거나 관리하지 않고도 대규모 데이터를 쿼리하고 분석할 수 있는 간편한 방법을 제공합니다.
Athena는 데이터를 스캔하고 SQL 쿼리를 실행하여 결과를 반환합니다. 데이터를 처리하기 위해 별도의 서버를 설정하거나 관리할 필요가 없으며, 필요한 만큼의 용량을 사용하고 쿼리한 양에 따라 비용을 지불하게 됩니다.
기존의 데이터를 활용하여 분석, 리포트 작성, 비즈니스 인텔리전스 등에 활용할 수 있습니다.
주로 대용량의 로그 데이터, 트랜잭션 데이터, IoT 데이터 등을 분석하는 데 유용하며, 데이터를 S3에 저장했다면 Athena를 사용하여 손쉽게 분석할 수 있습니다.
실습환경
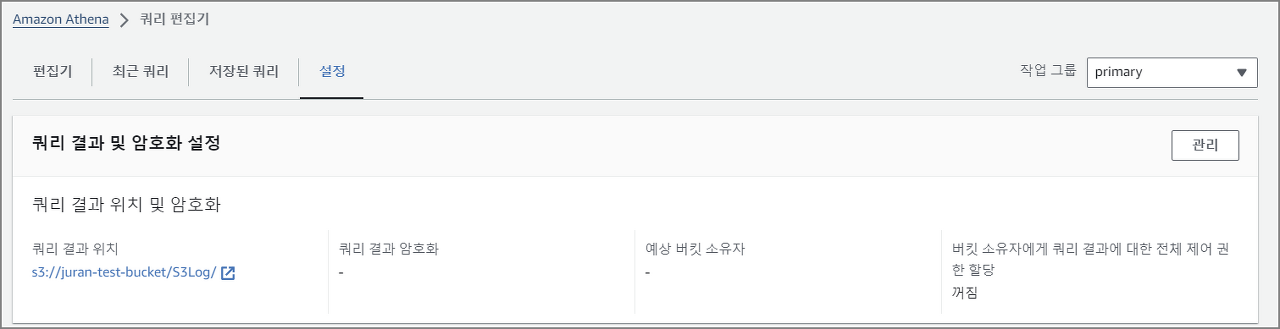
1. 쿼리 결과 위치 설정
- 쿼리의 결과를 담을 버킷을 결정
2. database 생성
create database s3_access_logs_db
3. 테이블 생성 (파티셔닝 필요)
- 버킷 네임에 유의
CREATE EXTERNAL TABLE `s3_access_logs_db.mybucket_logs`(
`bucketowner` STRING,
`bucket_name` STRING,
`requestdatetime` STRING,
`remoteip` STRING,
`requester` STRING,
`requestid` STRING,
`operation` STRING,
`key` STRING,
`request_uri` STRING,
`httpstatus` STRING,
`errorcode` STRING,
`bytessent` BIGINT,
`objectsize` BIGINT,
`totaltime` STRING,
`turnaroundtime` STRING,
`referrer` STRING,
`useragent` STRING,
`versionid` STRING,
`hostid` STRING,
`sigv` STRING,
`ciphersuite` STRING,
`authtype` STRING,
`endpoint` STRING,
`tlsversion` STRING)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://bucketname/'
4. 테이블 미리보기
- 쿼리를 넣고 테이블을 미리 볼 수 있음

5. 특정 기간에 GET 요청이 많았던 시간 별로 확인
SELECT
date_trunc('hour', parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')) AS hour,
count(*) AS count_get_requests
FROM s3_access_logs_db.mybucket_logs
WHERE
operation = 'REST.GET.OBJECT'
AND parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')
BETWEEN timestamp '2023-11-22 00:00:00'
AND timestamp '2023-11-22 17:00:00'
GROUP BY
date_trunc('hour', parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z'))
ORDER BY
count_get_requests DESC
LIMIT 10;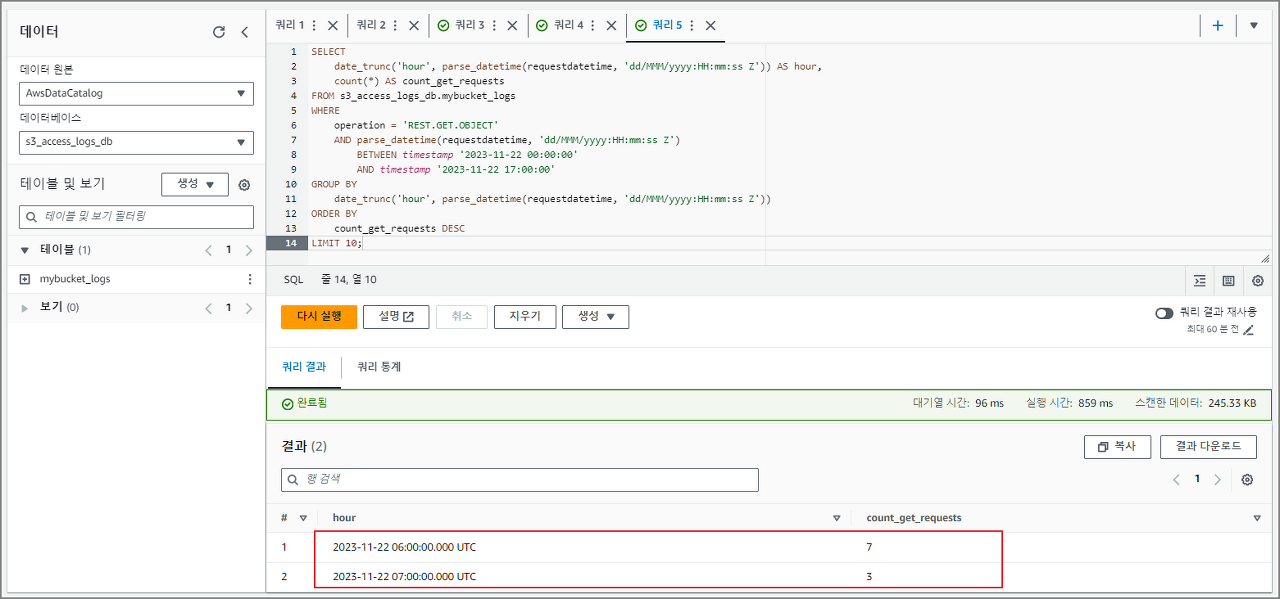
6. 시간별로 그룹화 된 GET 요청 횟수를 requester 정보와 함께 시간별 GET 요청 통계
SELECT
date_trunc('hour', parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')) AS hour,
requester,
count(*) AS count_get_requests
FROM s3_access_logs_db.mybucket_logs
WHERE
operation = 'REST.GET.OBJECT'
AND parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')
BETWEEN timestamp '2023-11-22 00:00:00'
AND timestamp '2023-11-22 17:00:00'
GROUP BY
date_trunc('hour', parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')),
requester
ORDER BY
count_get_requests DESC
LIMIT 20;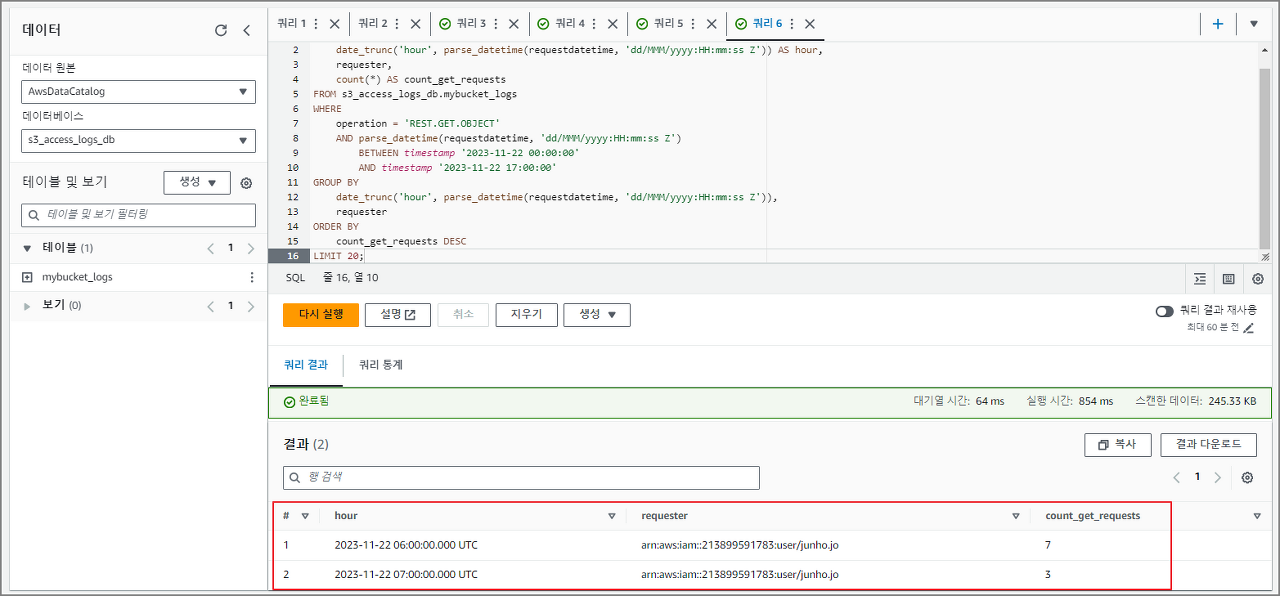
이렇게 간단하게 로그를 분석하고 나아가 원인과 결과 혹은 예방에 대한 인사이트까지 확인할 수 있습니다.
오늘도 유익한 시간이었길 바라며!
다음 시간에도 유익한 정보로 찾아올게요 !

베 빠 - !
'CSP (Cloud Service Provider) > AWS' 카테고리의 다른 글
| [AWS] AWS EMR (0) | 2023.12.22 |
|---|---|
| AWS Quantum Ledger Database (QLDB) (1) | 2023.12.22 |
| S3 Access log & Lambda &CloudWatch (0) | 2023.12.20 |
| [AWS] S3 Access log 활성화 방법 (0) | 2023.12.20 |
| [AWS] AWS DataSync-EFS (0) | 2023.12.20 |




댓글