안녕하세요 비티시보이즈입니다.
오늘 포스팅 주제는 AWS EMR입니다.
Amazon EMR 이란?
Apache Spark, Hive, Presto 및 다른 빅 데이터 워크로드를 손쉽게 실행하고 크기를 조정할 수 있는 AWS 서비스입니다.
EKS 기반 Amazon EMR은 Amazon EKS (Amazon Elastic Kubernetes Service) 에서 오픈 소스 빅 데이터 프레임워크를 실행할 수 있는 Amazon EMR용 배포 옵션을 제공합니다. 이 배포 옵션을 사용하면 EKS 기반 Amazon EMR이 오픈 소스 애플리케이션용 컨테이너를 구축, 구성 및 관리하는 동안 분석 워크로드를 실행하는 데 집중할 수 있습니다.
- 인프라를 프로비저닝하지 않고도 공통 리소스 풀에서 애플리케이션을 실행할 수 있습니다. EKS 클러스터에서 실행되는 분석 애플리케이션을 개발, 제출 및 진단합니다.
- 인프라 팀은 공통 컴퓨팅 플랫폼을 중앙에서 관리하여 Amazon EMR 워크로드를 다른 컨테이너 기반 애플리케이션과 통합할 수 있습니다.
- 일반적인 Amazon EKS 도구를 사용하여 인프라 관리를 간소화하고, 다양한 버전의 오픈 소스 프레임워크가 필요한 워크로드에 공유 클러스터를 활용할 수 있습니다.
- 자동화된 Kubernetes 클러스터 관리 및 OS 패치를 통해 운영 오버헤드를 줄일 수 있습니다. Amazon EC2와 함께AWS Fargate여러 컴퓨팅 리소스를 활성화하여 성능, 운영 또는 재무 요구 사항을 충족할 수 있습니다.
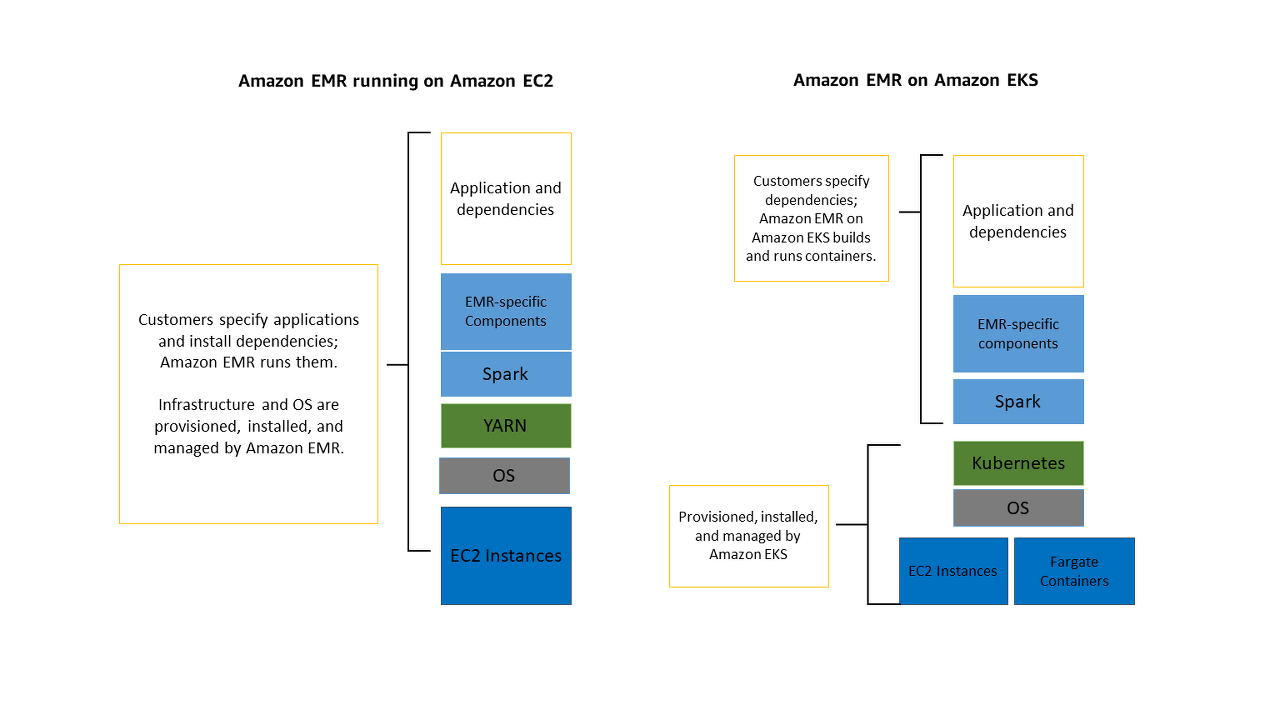
아래의 그림은 Amazon EMR용 두 가지 배포 모델입니다.
아래는 EKS 기반 Amazon EMR 워크플로입니다.
- 기존 Amazon EKS 클러스터를 사용하거나 eksctl 유틸리티 또는 Amazon EKS 콘솔로 사용합니다.
- EKS 클러스터의 네임스페이스에 Amazon EMR을 등록하여 가상 클러스터를 생성합니다.
- AWS CLI또는 SDK를 사용하여 가상 클러스터에 작업을 제출합니다.
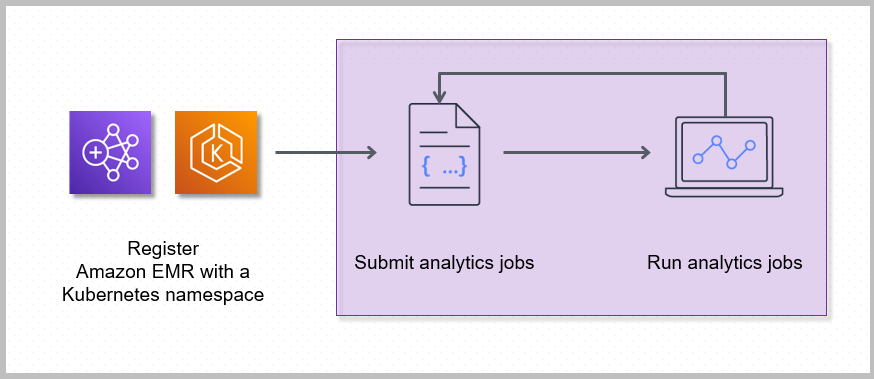
Amazon EKS에서 쿠버네티스 네임스페이스에 Amazon EMR을 등록하면 가상 클러스터가 생성됩니다. 그러면 Amazon EMR이 해당 네임스페이스에서 분석 워크로드를 실행할 수 있습니다. EKS에서 Amazon EMR을 사용하여 Spark 작업을 가상 클러스터에 제출하면 EKS의 Amazon EMR은 Amazon EKS의 쿠버네티스 스케줄러에 파드를 스케줄링하도록 요청합니다.
EKS 기반 Amazon EMR은 사용자가 실행하는 각 작업에 대해 Amazon Linux 2 기본 이미지, Apache Spark 및 관련 종속성을 포함하는 컨테이너를 생성합니다. 각 작업은 컨테이너를 다운로드하고 실행을 시작하는 포드에서 실행됩니다. 작업이 종료된 후에 포드가 종료됩니다. 컨테이너의 이미지가 이전에 노드에 배포된 경우 캐시된 이미지가 사용되고 다운로드가 우회됩니다. 로그 또는 메트릭 전달자와 같은 사이드카 컨테이너를 포드에 배포할 수 있습니다. 작업이 종료된 후에도 Amazon EMR 콘솔에서 Spark 애플리케이션 UI를 사용하여 작업을 디버깅할 수 있습니다.
마무리 하겠습니다.
EMR은 주로 대용량 데이터 처리, 데이터 분석, 머신 러닝 작업 등에 사용되며, 특히 정형 및 비정형 데이터에 대한 복잡한 분석 및 처리 요구사항을 충족시키기 위해 설계되었습니다.
Amazon EMR은 Amazon Web Services(AWS)에서 제공하는 클라우드 기반의 관리형 클러스터 서비스입니다.
EMR은 대량의 데이터를 처리하고 분석하기 위한 오픈 소스 기반의 분산 컴퓨팅 프레임워크인 Apache Hadoop 및 Apache Spark를 기반으로 합니다. EMR은 다양한 애플리케이션 및 프레임워크를 사용하여 대규모 데이터 세트에 대한 분석 및 처리 작업을 수행할 수 있습니다.
주요 특징 및 용도:
1. 분산 데이터 처리: EMR은 데이터를 여러 노드에 분산하여 처리하므로 대용량의 데이터에 대한 효율적인 처리가 가능합니다.
2. 다양한 프레임워크 지원: Apache Hadoop, Apache Spark, Apache Hive, Apache HBase, Apache Flink 등의 분산 컴퓨팅 및 데이터 처리 프레임워크를 지원합니다.
3. 유연한 확장성: 필요에 따라 클러스터의 크기를 쉽게 조절할 수 있어서 작업 부하에 따라 자동으로 클러스터를 확장하거나 축소할 수 있습니다.
4. 관리형 서비스: 클러스터의 설정, 모니터링, 로깅 및 유지 관리를 AWS가 자동으로 처리하므로 사용자는 클러스터의 운영에 대해 걱정할 필요가 없습니다.
5. 저렴한 비용 모델: 필요한 만큼의 컴퓨팅 리소스를 사용하고 사용한 만큼만 비용을 지불하므로 비용을 효율적으로 관리할 수 있습니다.
6. 클라우드 기능 통합: EMR은 AWS의 다른 서비스와 쉽게 통합되어 S3 (Simple Storage Service), Amazon RDS, Amazon DynamoDB 등과 함께 사용할 수 있습니다.
이상으로 포스팅 마치겠습니다.
감사합니다.
'CSP (Cloud Service Provider) > AWS' 카테고리의 다른 글
| [AWS] AWS DataSync - S3 (1) | 2023.12.26 |
|---|---|
| [AWS] RDS AuroraMysql 엔진버전 업그레이드 (1) | 2023.12.22 |
| AWS Quantum Ledger Database (QLDB) (1) | 2023.12.22 |
| [AWS] Athena로 S3 AcceseLog 분석하기 (0) | 2023.12.21 |
| S3 Access log & Lambda &CloudWatch (0) | 2023.12.20 |




댓글