안녕하세요 이번 시간에는 AWS에서 제공한는 AI/ML 서비스인 SageMaker에 대해 알아보려고 합니다람쥐.
그럼 우선 Machine Learning이 어떤 방식으로 이루어 지는지를 알아야 각 단계별 어떤 서비스들이 SageMaker에 구성되어있는지 알겠죠랑말?
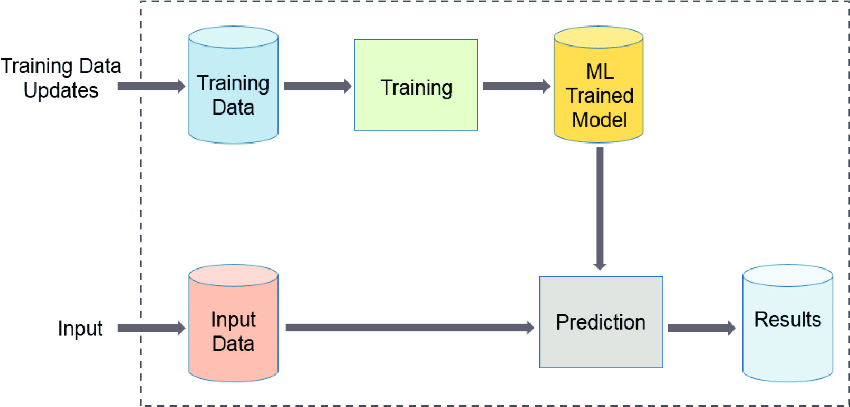
기계학습은 크게 학습을 하는 단계와 예측을 하는 단계로 이루어저 있습니다.
즉 이미 Input과 Output 즉 정답지를 통해서 학습을 시키고 이를 통해 만들어진 Trained Model을 통해 새로운 Input에 대해 결과를 예측하는 것이 Machine Learning 입니다.
보통 AWS로 SageMaker를 구축할 경우 Datalake도 구축을 하여 데이터를 수집하고 저장하는 단계도 추가되기도 합니다. 하지만 이번에는 SageMaker에 집중하기로 하겠습니다.
Training Data는 이미 정제된 데이터로 Training을 위한 알고리즘의 세부적인 값들을 조정하는 위한 값들 입니다.
쉽게 말하면
ax+by+c=0이라는 식이 있다고 합시다.
여기서 x, y값에는 Training 데이터 말그대로 Input값인 x 와 Output인 y가 들어가게 됩니다.
그래서 x y 값 즉 Training data를 많이 넣어서 최대한 모든 값에 근사한 정답을 유추할 수 있는 a b c 값을 찾는 것이 중요합니다.
이렇게해서 a b c 값을 찾아서 만들어 진 식이 ML Trained Data라고 생각하면 됩니다.
이렇게 완성된 식을 가지고 새로운 x값을 가지고 새로운 y 값을 유추하는 것이 ML의 기본 원리 입니다.
즉 x와 y에 대한 값을 가지고 a b c의 값을 찾아내어 새로운 x 값이 나왔을때 y값을 추측 할 수 있도록 하는 것이 바로 기계학습입니다.
그럼 SageMaker는 이를 위해 어떤 서비스들을 가지고 있는지 보도록 하겠습니다.

다음과 같이 각 단계별로 SagmeMaker는 많은 서비스들을 제공해주고 있습니다. 내가 어떤 단계에 있는지를 파악하고 어떤 서비스가 필요한지 판단하고 사용하면 됩니다. 그러면 기계학습을 AWS를 활용해서 진행할 경우 장점이 무엇일까요?
기계학습을 하기 위해서는 높은 사향의 컴퓨터가 필요로 합니다. 여기서는 CPU와 GPU의 차이를 조금 알면 좋지만 간단하게 설명하면
CPU : 대학 교수
GPU: 사칙연산 마스터한 중학생 정도?
딱 저렇게만 보면 CPU가 좋은거 아닌가? 라는 생각이 듭니다. 하지만 실제에서도 대학 교수 보다 학생이 더 많듯이 컴퓨터에는 CPU가 한번에 많은 일을 할 수 는 없습니다. 즉 어렵고 복잡한 일은 CPU가 간단하지만 노가다 업무가 많은 일은 GPU가 하게 됩니다.
그럼 기계학습은 어디에 해당 될까요? 100만개가 넘는 Training data를 가지고 a b c 값을 찾는 단순하지만 업무양이 많은 기계학습은 GPU를 사용하여 이루어집니다. 하지만 GPU가격이 어마어마하죠...
그레서 AWS를 통해 기계학습을 구축하면 Serverless 환경으로 기계학습을 시행할 수 있습다. 즉 Training 하는 시간이나 예측하는 시간 즉 GPU를 필요로하는 시간에 사용한 비용만 지불하면 됩니다.
즉 기계학습을 위해 기계를 살 필요도 단순 클라우드 환경에서 인스턴스를 만들어서 유지비용을 지불할 필요도 없습니다. 사용한 시간만 자동으로 측정되어 비용을 지불하면 됩니다.
이외에도 여러 Saas 서비스들을 바탕으로 고객의 니즈에 따라 빠르게 대응하고 새로운 기능들을 쉽게 추가할 수 있습니다.
그럼 오늘은 여기까지 하도록 하겠습니다람쥐!!
ㅃㅇ~~
'CSP (Cloud Service Provider) > AWS' 카테고리의 다른 글
| AWS Spot Instance (0) | 2022.11.28 |
|---|---|
| AWS 글로벌 인프라 구성- 1 (0) | 2022.11.28 |
| AWS FIS (0) | 2022.11.28 |
| CloudFront 정책과 보안 (0) | 2022.11.25 |
| CloudFront 다양한 기능 (0) | 2022.11.24 |




댓글